Análisis LL (1)
Antes de
entrar en detalles, conviene definir las gramáticas LL (1), ya
que el analizador que se va a estudiar después, sólo
trabaja con este tipo de gramáticas.
Para que
una gramática sea LL (1) debe cumplir una serie de
condiciones:
No debe
ser ambigua. Una gramática es ambigua si una cadena puede
ser generada por dos árboles sintácticos diferentes.
Para eliminar la ambigüedad no existe un algoritmo concreto,
sólo se resuelve modificando la gramática
adecuadamente.
No puede
ser recursiva por la izquierda. Una gramática es recursiva por
la izquierda si tiene un no terminal S
tal que exista una derivación del tipo
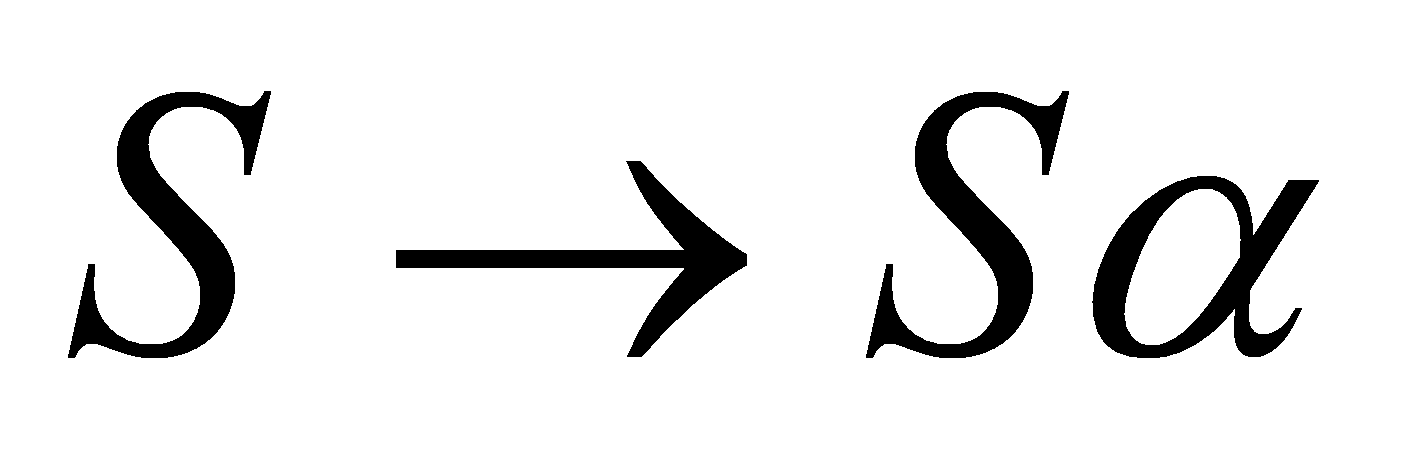 . .
La
construcción de un analizador sintáctico predictivo no
recursivo es sencilla, el esquema sería el siguiente:
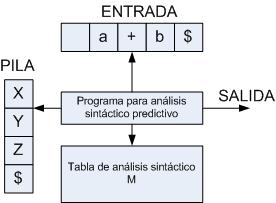
Figura
37: Modelo de un analizador sintáctico predictivo.
Un
analizador sintáctico predictivo no recursivo tiene los
siguientes componentes:
Buffer
de entrada: El buffer de entrada contiene la cadena de entrada a
ser analizada. Para poder conocer cuando se acaba la cadena de
entrada se pone un símbolo especial ($) al final del
buffer.
Pila:
Sirve para ir registrando el proceso de derivación,
inicialmente contiene el símbolo inicial de la gramática.
Tabla
de análisis sintáctico: La tabla de análisis
le indica al programa analizador la producción que debe
expandir con la configuración actual (símbolo en la
cima de la pila y primer símbolo de la entrada).
Programa
de análisis: Es el programa de control del analizador
sintáctico.
El
funcionamiento del analizador sintáctico es el siguiente: En
cada momento el programa de control mira el símbolo que hay en
la cima de la pila y en el buffer de entrada, dependiendo de estos
símbolos se procede de diferentes formas, como se verá
en el algoritmo:
Si el
símbolo de la cima de la pila y el de la entrada es el mismo y
es el símbolo final ('$'), entonces la cadena de entrada se ha
reconocido con éxito.
Si el
símbolo de la cima de la pila es igual al de la entrada (pero
diferente al símbolo final), entonces se avanza al
siguiente símbolo de la entrada y se elimina el símbolo
de la cima de la pila.
Si el
símbolo de la cima de la pila es un no terminal, el programa
de control consulta en la tabla de análisis qué
producción expandir.
Para
consultar la tabla, como índice de fila se utiliza el símbolo
de la cima de la pila y como índice de columna, el símbolo
de la cabecera del buffer de entrada. Si al realizar la consulta, el
valor de la entrada indica que es un error, significa que no hay
ninguna producción válida. Por lo tanto, hay un error
sintáctico y la cadena de entrada no es válida. Si no
es una entrada errónea, dicha entrada indicará la
producción por la cual hay que realizar la expansión.
Para realizar la expansión lo que se hace es eliminar el no
terminal de la cima de la pila e introducir en orden inverso la parte
derecha de la producción a expandir
En el
siguiente algoritmo (Algoritmo 4) se muestra este proceso de manera
formal.
Entrada:
Una cadena de entrada y una tabla de análisis sintáctico.
1: /*P
y E son los símbolos que están en la cima de la pila y
como símbolo actual de la entrada, respectivamente. "$"
es el símbolo final*/
2:
repeat
3:
if P
es un terminal o P
== E
then
4:
if P
== E
then
5: Eliminar
símbolo de la cima de la Pila y avanzar la entrada al
siguiente símbolo
6:
else
7:
Error.
8:
end if
9:
else
10:
if Tabla
[P,
E]
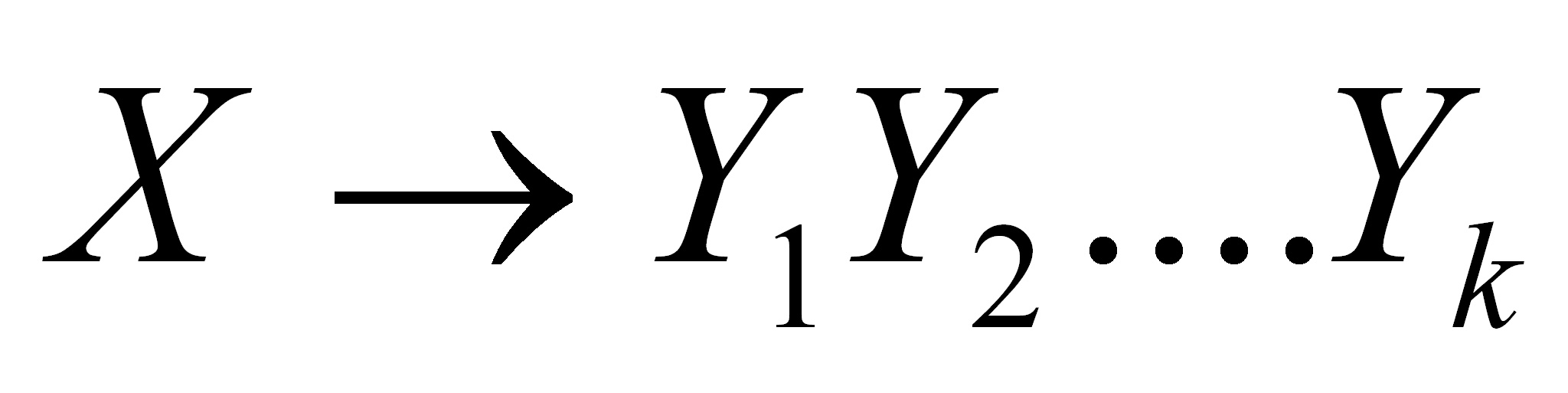 then
then
11:
Eliminar cima de la pila.
12:
Meter en la pila
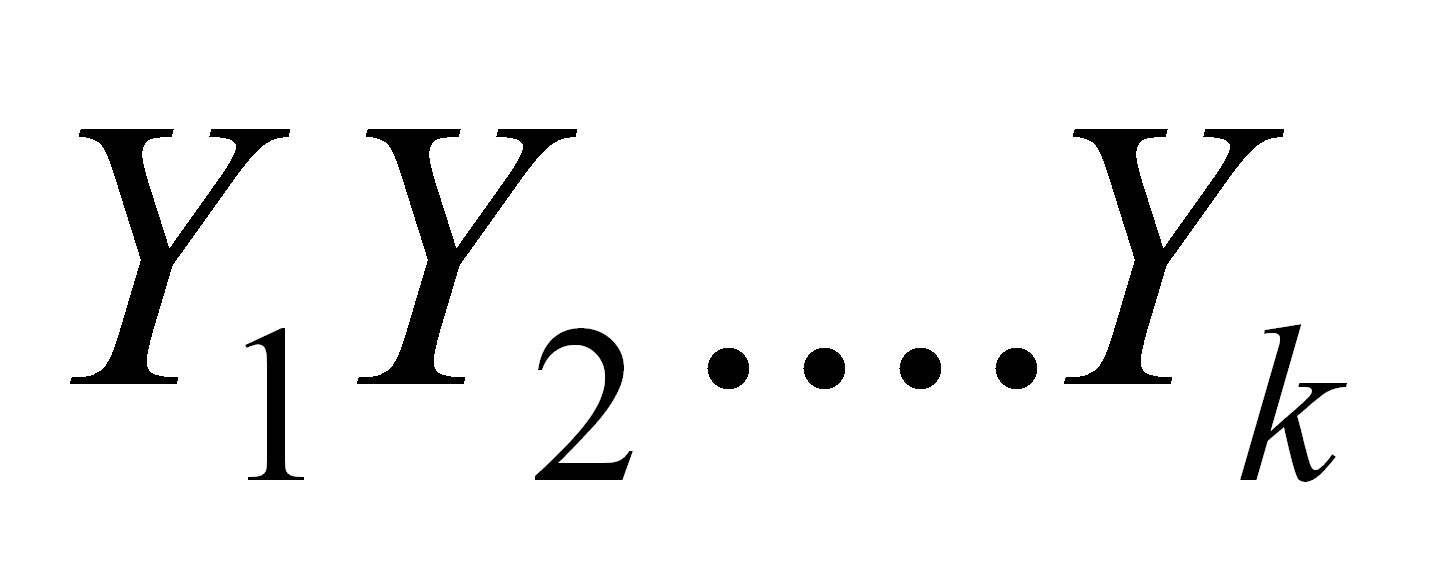 en
orden inverso dejando en
orden inverso dejando
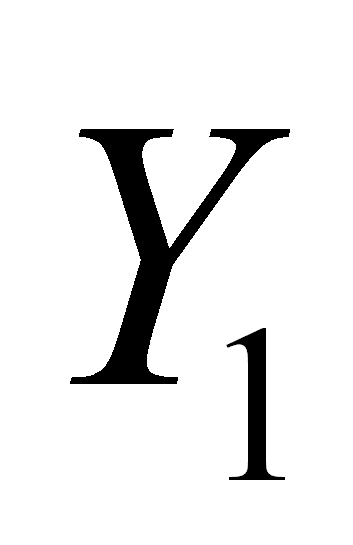 en la cima.
en la cima.
13:
else
14:
Error.
15:
end if
16:
end if
17:
until P == $
Algoritmo
4: Algoritmo de cálculo
de análisis sintáctico predictivo no recursivo.
Dada la
siguiente gramática:
E
→T E
E→+
T E | ε
T→F
T
T→*
F T | ε
F
→ (E) | id
En
la siguiente tabla (tabla1) se muestra una traza para una entrada id
+ id * id
|
Pila
|
Entrada
|
Producción
|
|
$
E
|
id
+ id * id $
|
T[E,
id] = E →T E
|
|
$
E T
|
id
+ id * id $
|
T[T,
id] = T → F T
|
|
$
E T F
|
id
+ id * id $
|
T[F,
id] = F → id
|
|
$
E T id
|
id
+ id * id $
|
|
|
$
E T +
|
id
* id $
|
T[T,
+] = T → ε
|
|
$
E
|
+
id * id $
|
T[E,
+] = E →+ T E
|
|
$
E T +
|
+
id * id $
|
|
|
$
E T
|
id
* id $
|
T[T,
id] = T →F T
|
|
$
E T F
|
id
* id $
|
T[F,
id] = F → id
|
|
$
E T id
|
id
* id $
|
|
|
$
E T
|
*
id $
|
T[T,
*] = T → * F T
|
|
$
E T F *
|
*
id $
|
|
|
$
E T F
|
id
$
|
T
[F, id] = F → id
|
|
$
E T id
|
id
$
|
|
|
$
E T
|
$
|
T[T,
$] = T ε
|
|
$
E
|
$
|
T[E,
$] = E → ε
|
|
$
|
$
|
Aceptar
|
Tabla
1: Traza de análisis LL1
para la entrada id + id * id
Generación de la tabla de
análisis LL (1)
Una vez se
ha visto el funcionamiento del analizador sintáctico, se
explicará la generación de la tabla de análisis.
La idea
básica de la construcción de la tabla es la siguiente:
Si se
tiene una producción del tipo X→α y además se tiene el conjunto
de iniciales de α, entonces cuando en la cima de la pila se
encuentre el no terminal X
y a la entrada alguno de los miembros del FIRST de α, hay que
utilizar la producción X→α
para realizar la expansión.
Si además,
X es anulable,
también hay que realizar la expansión por esta
producción en el FOLLOW de X.
En el siguiente algoritmo (Algoritmo 5) se
puede ver este proceso.
Salida:
Tabla de análisis (Tabla)
1: for
cada producción
 do
do
2:
for all c
 FIRST
[ FIRST
[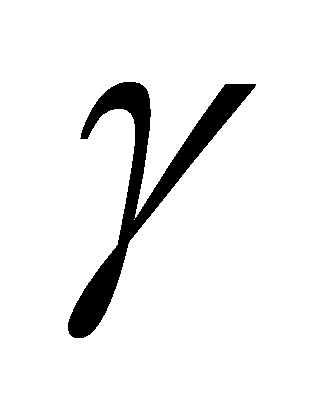 ]
do ]
do
3: Tabla
[X, c]:= Tabla [X, c]
4:
end for
5: if
esAnulable ()
then
6:
for all a
FOLLOW[X]
do
7:
Tabla [X, a]:= Tabla [X, a]
 {
} {
}
8:
end for
9:
end if
10: end
for
Algoritmo
5: Algoritmo de cálculo
de la tabla de análisis LL1.
Al generar
la tabla de análisis puede plantearse un problema: si en la
tabla hay entradas con definiciones múltiples. Entonces
significa que la gramática no es LL (1) y habrá que
comprobar si es ambigua o es recursiva por la izquierda o hay que
factorizarla por la izquierda.
En
la siguiente tabla se muestra la tabla LL1 para la gramática
anterior. Como se puede ver, no presenta ningún conflicto LL1
|
|
id
|
+
|
*
|
(
|
)
|
$
|
|
E
|
E → T
E
|
|
|
E
→ T E
|
|
|
|
E
|
|
E→+
T E
|
|
|
E →
ε
|
E →
ε
|
|
T
|
T →F
T
|
|
|
T →F
T
|
|
|
|
T
|
|
T
→ ε
|
T
→ * FT
|
|
T
→ ε
|
T
→ ε
|
|
F
|
F→id
|
|
|
|
|
|
Tabla
2: Tabla de análisis LL1
|
